Running MIRA in Docker Desktop with Illumina Data
![]()
This documentation assumes you have pulled the MIRA docker image into your Docker Desktop App. If not, please start with getting started instructions.
Stage your demultiplexed data
- In your “MIRA_NGS” folder, make a folder for your run. It is very helpful to name your runs with a consistent naming system, such as “YEAR-MONTH-DATE-FLOWCELL_ID”, ie. 2022-11-13-ABC1234.
DO NOT PUT SPACES OR SLASHES IN YOU RUN FOLDER NAMES!
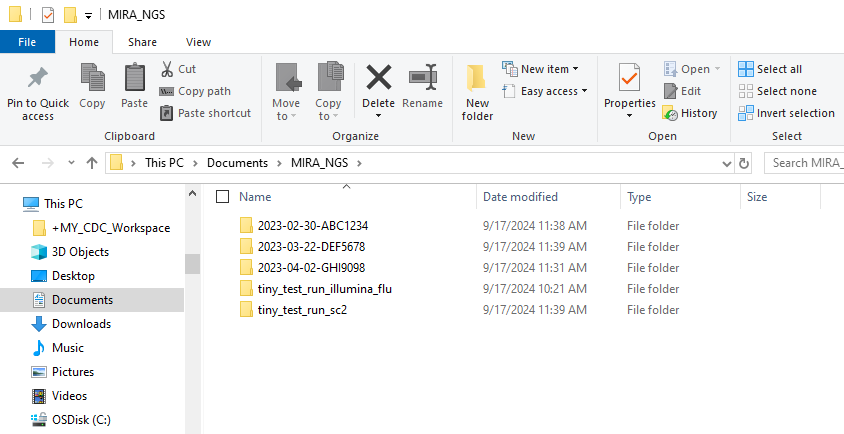
- Copy the run’s demultiplexed fastqs into the RUN-FOLDER.
- Create another folder inside your RUN-FOLDER called “fastqs” and copy the folder containing demultiplexed fastqs into this newly created fastqs folder so that the folder structure is MIRA_NGS/RUN-FOLDER/fastqs/demultiplexed-fastqs/sample-reads.fastq. There will be two fastq files per sample.
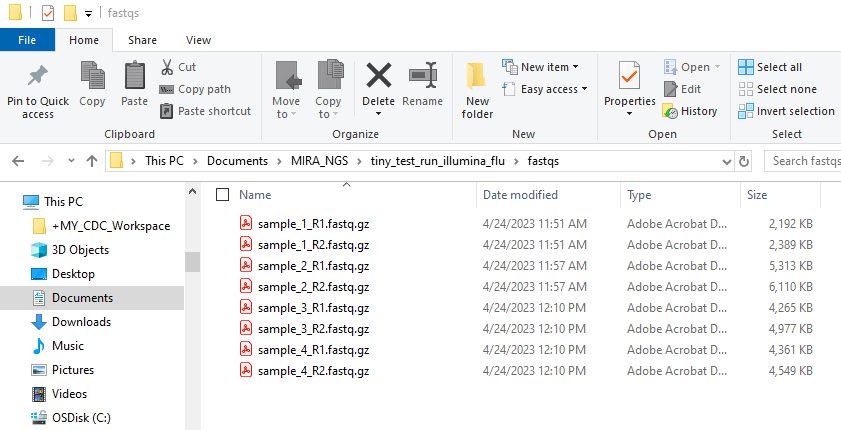
This screenshot shows a Windows file system. The file system set up may vary between users.
Run Genome Assembly with MIRA
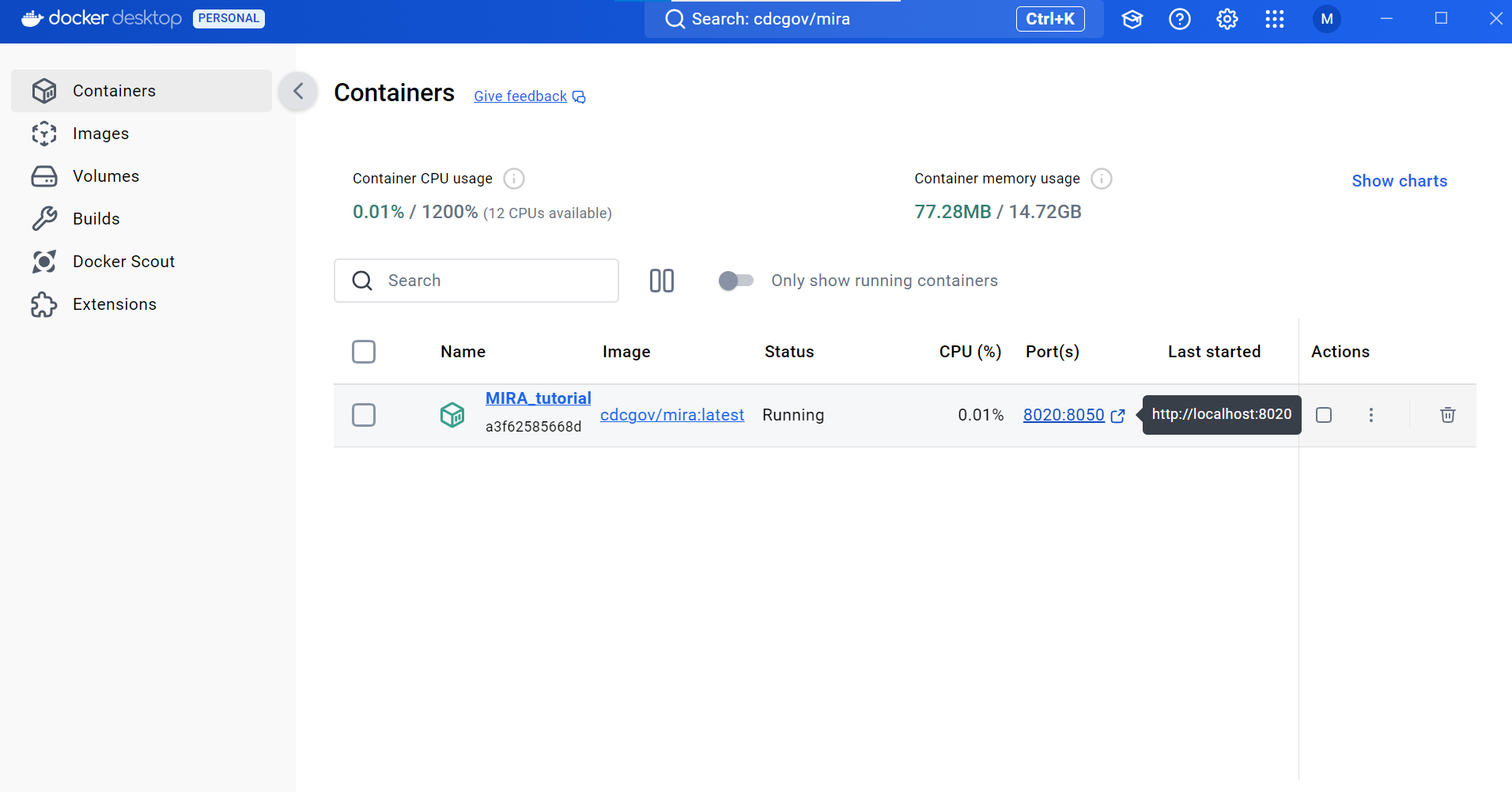
Open MIRA
- In Docker Desktop, open MIRA by clicking the blue link “8020:8050”. This will open MIRA into your default internet browser. You can “bookmark” this site in your browser.
Select run, data type, and enter sample information
-
Click the
REFRESH RUN LISTINGbutton and select your run from the dropdown box.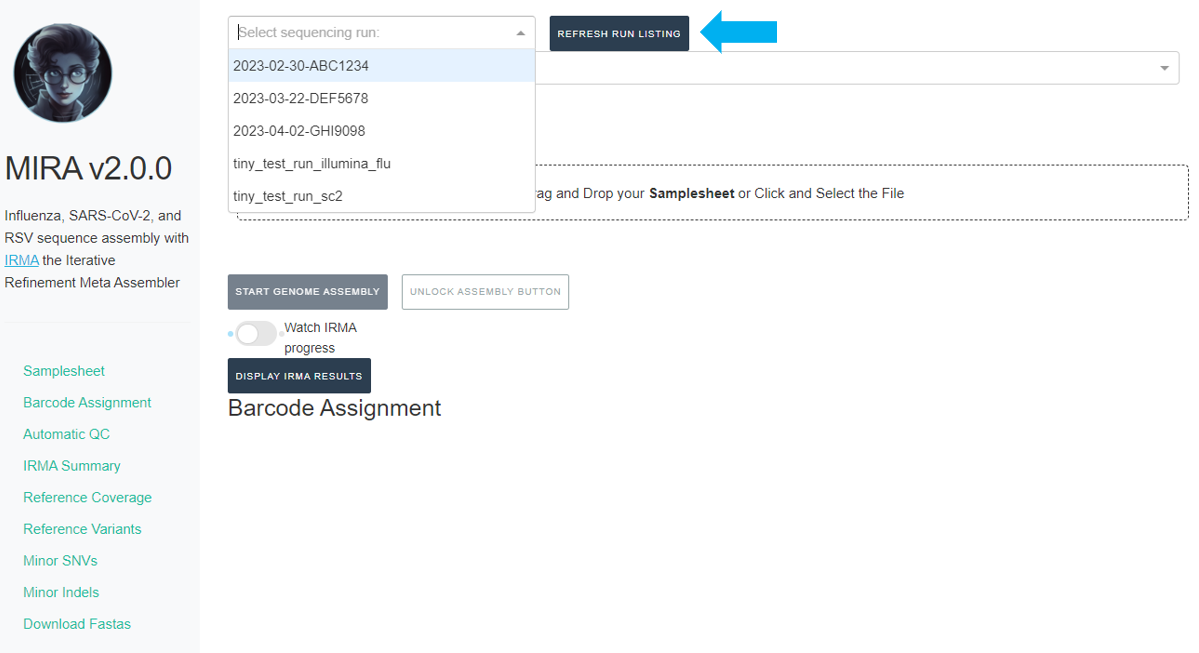
- Next, click the box that say “What kind of data is this” and select Flu-Illumina, SC2-Whole-Genome-Illumina or RSV-Illumina.
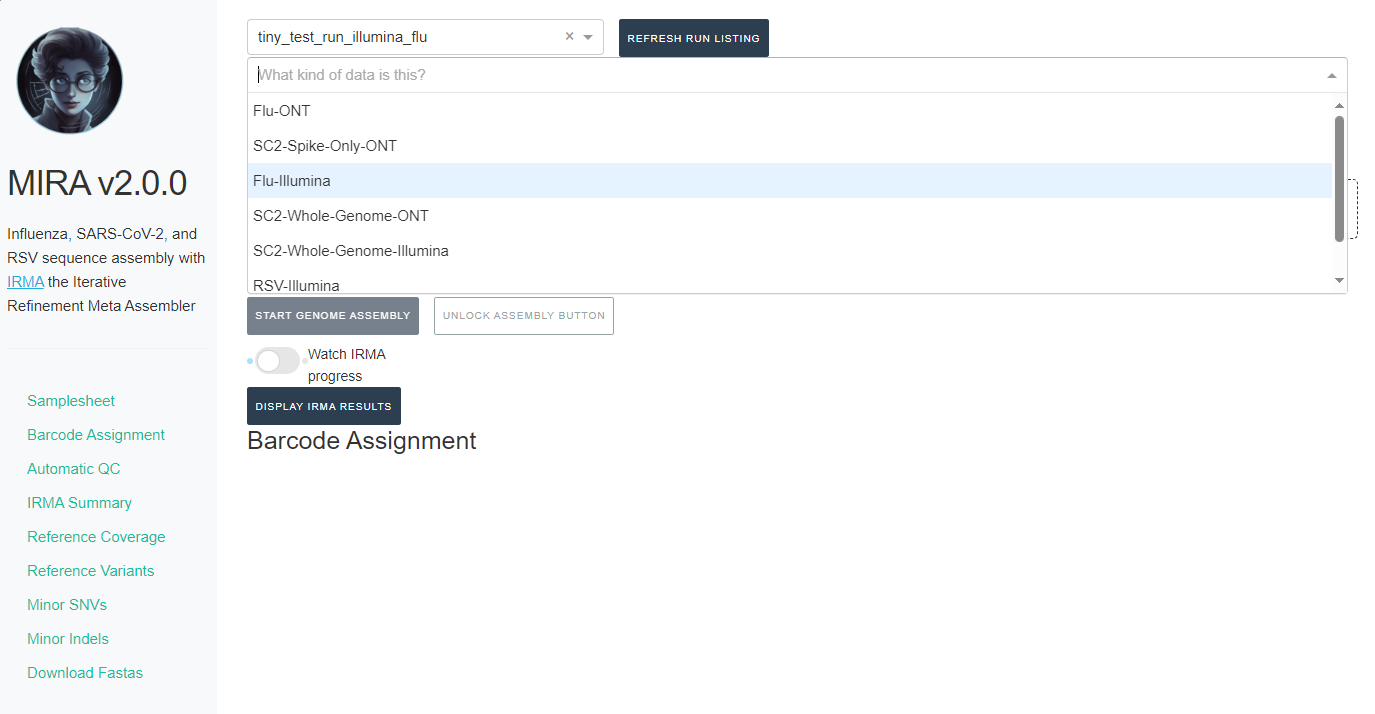
-
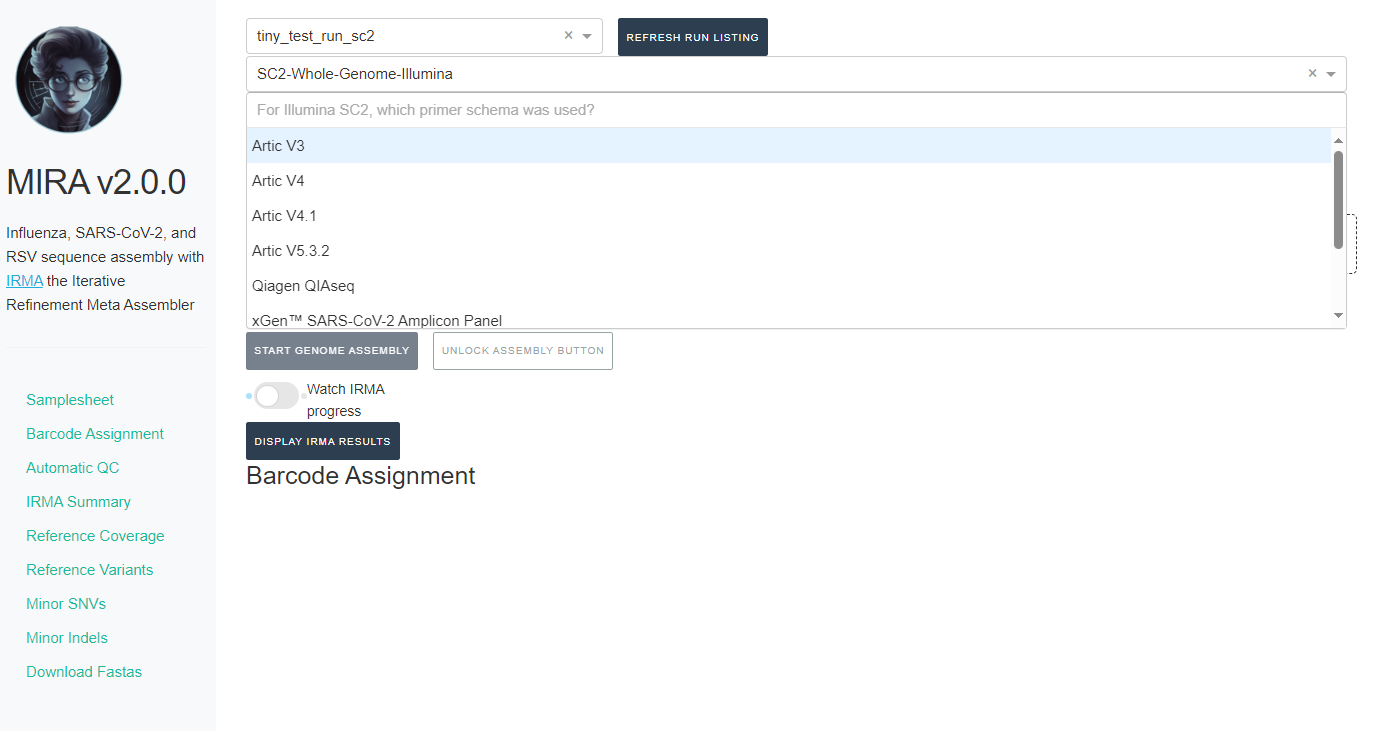
If you select SC2-Whole-Genome-Illumina or RSV-Illumina, a new box will appear for you to select your primer schema/amplicon approach
-
NOTE: MIRA SC2-Whole-Genome-Illumina and RSV-Illumina module’s
primer trimming steps have been tested and optimized for the primer
panels provided.
-
NOTE: MIRA SC2-Whole-Genome-Illumina and RSV-Illumina module’s
primer trimming steps have been tested and optimized for the primer
panels provided.
-
Next, click
DOWNLOAD SAMPLESHEET TEMPLATEand open the resulting Excel spreadsheet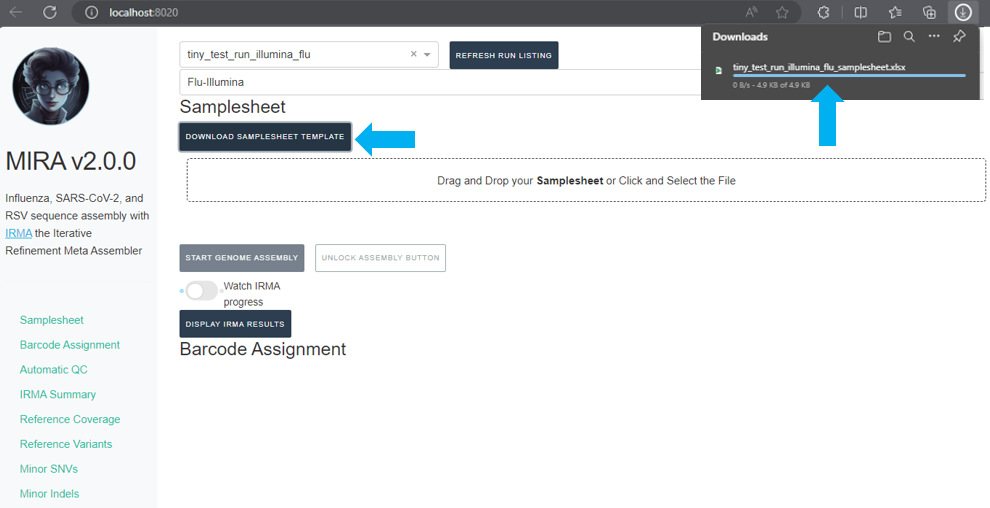
-
Your sample names will be inferred from the fastq filenames in your fastq directory. Do not change these sample names.
- If you do not see a sample that you expect, this is because that sample name does not have a fastq to process.
Next, select your
Sample Type. Most of your sample’s are test samples, so each row defaults totest, but select- controlor+ controlfor your negative and positive controls respectively.Save your samplesheet with changes in Excel
-
Back in MIRA, Click the “Drag and Drop your Samplesheet” to select your filled-in samplesheet.
- A table in the application should now appear with your samples!
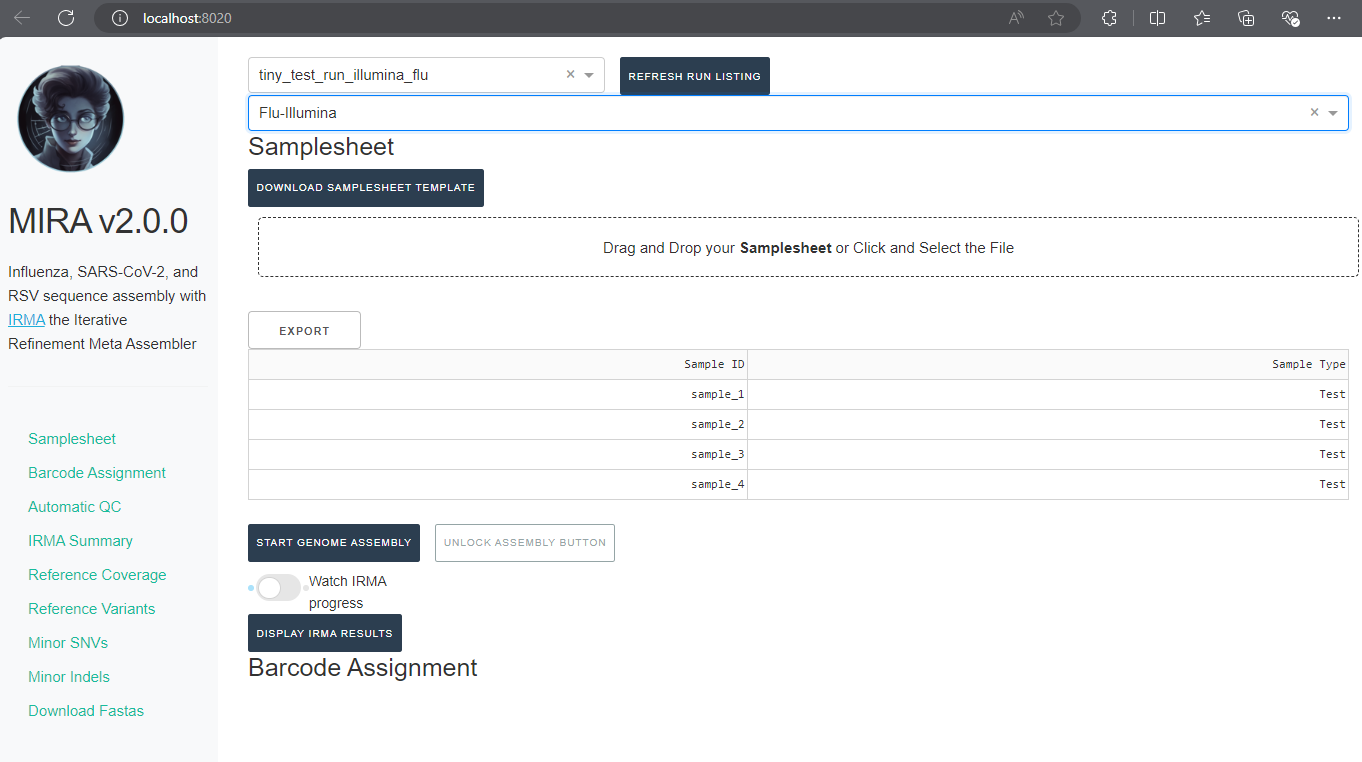
Start Genome Assembly
- Now select
UNLOCK ASSEMBLY BUTTONand clickSTART GENOME ASSEMBLY. Now is a good time to go have a coffee.Whole-Genome SARS-CoV-2 is the slowest assembly module as its genome is much larger than Influenza or RSV.
Click on the toggle button
Watch MIRA Progress. Assembly will take some time, how long exactly is dependent on your sample number, the number of raw sequencing reads, and the power of your computer.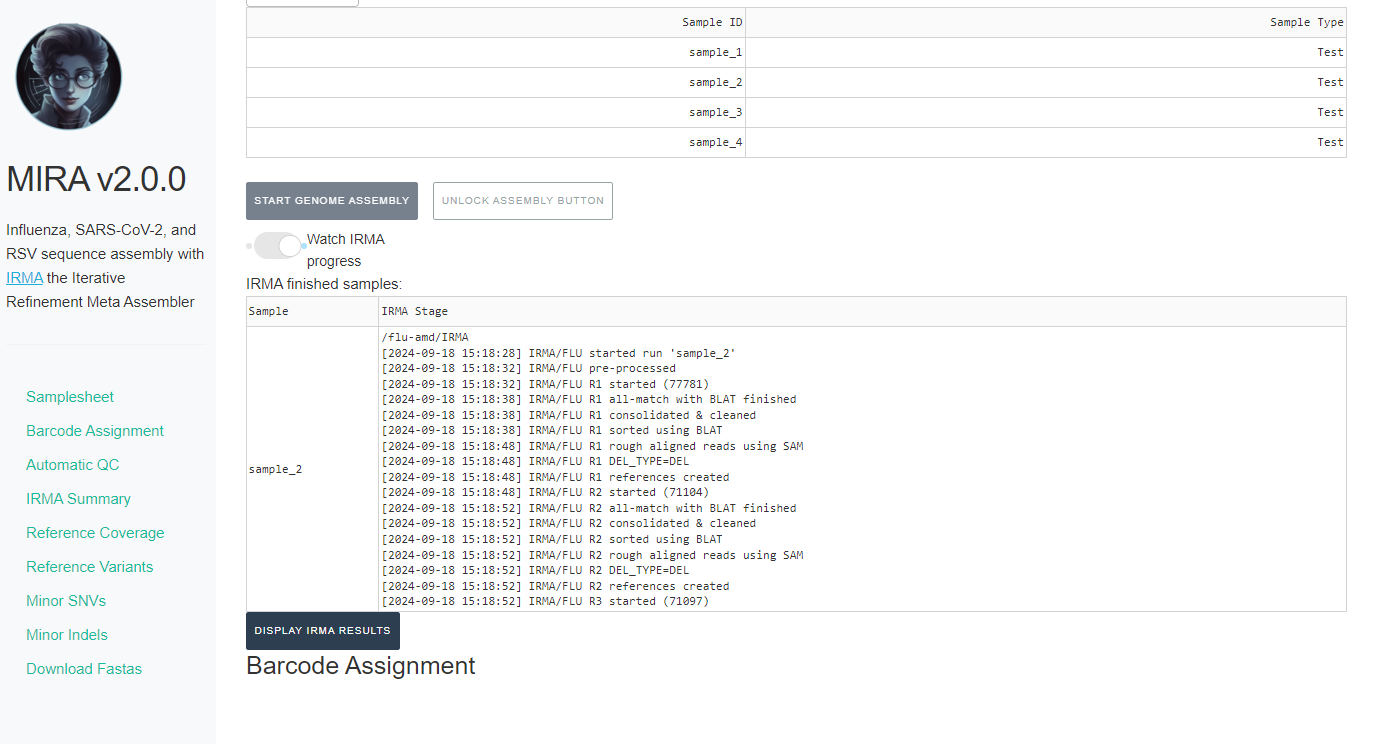
-
When MIRA has finished, it will say “MIRA is finished” and you can now click on “DISPLAY MIRA RESULTS”.
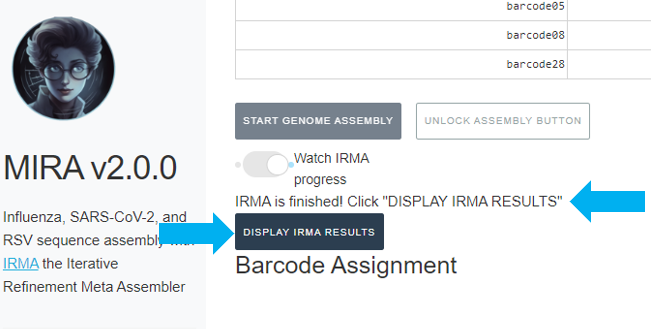
Review MIRA results
-
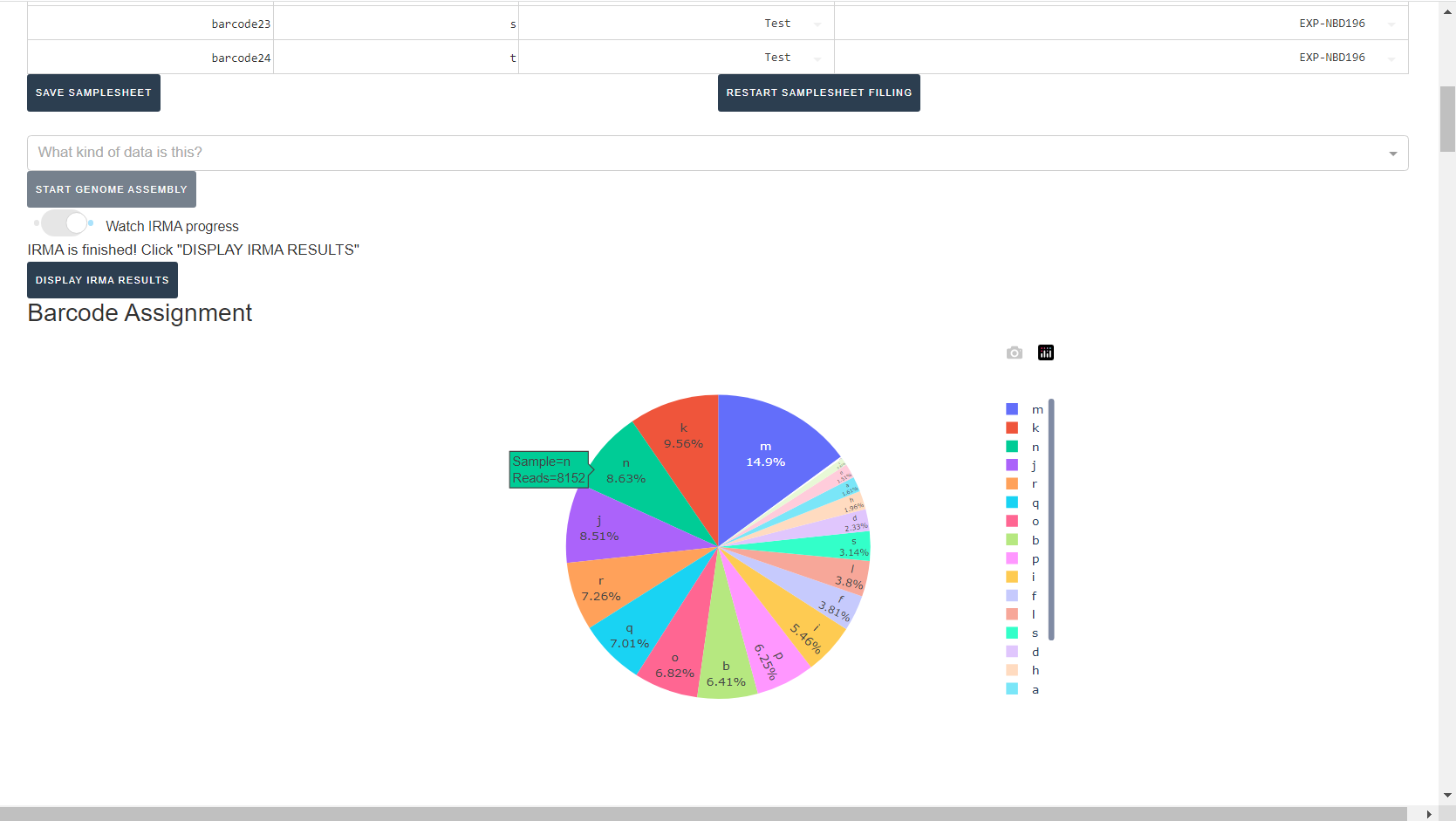
Review the distribution of reads assigned to each barcode. The ideal result would be a similar number of reads assigned to each test and positive control. However, it is ok to not have similar read numbers per sample. Samples with a low proportion of reads may indicate higher Ct of starting material or less performant PCR during library preparation. What is most important for sequencing assembly is raw count of reads and their quality.
-
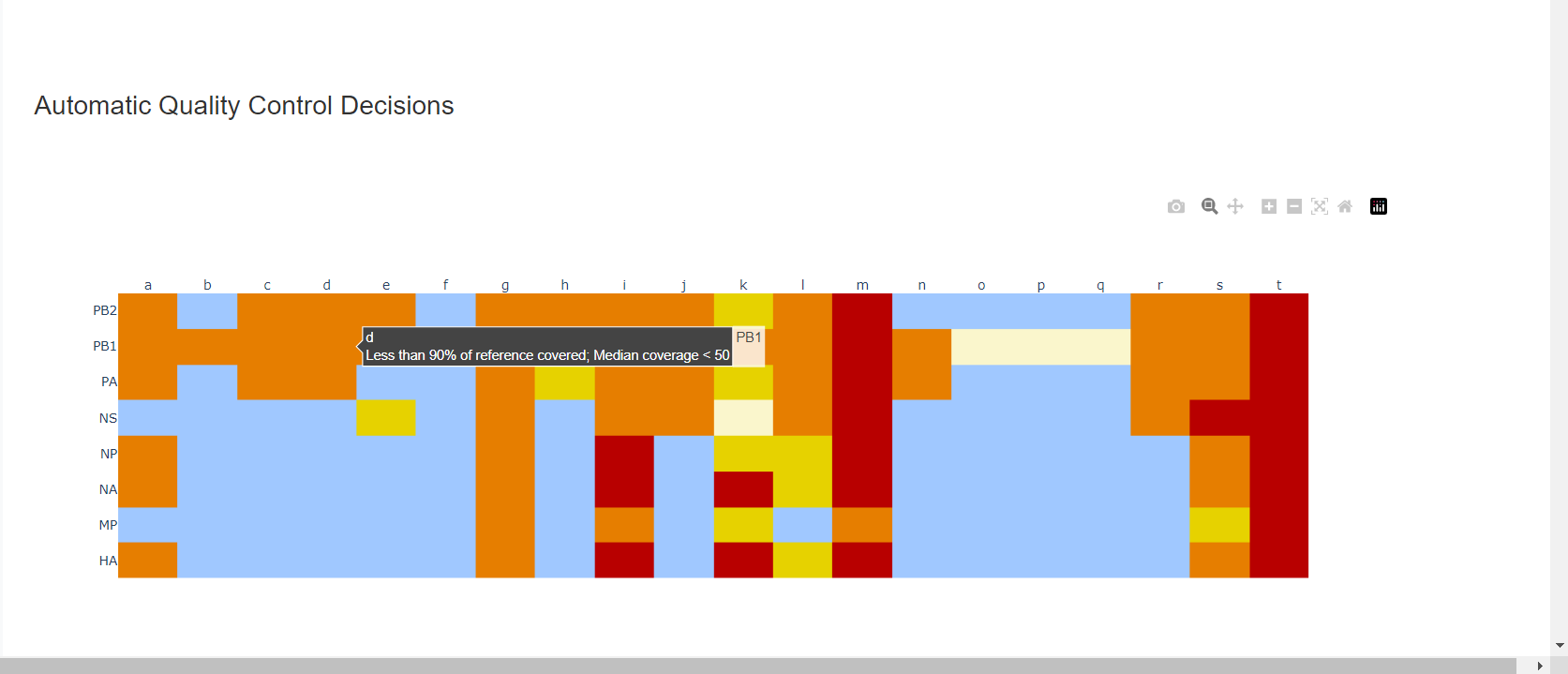
Review the “Automatic Quality Control Decisions” heatmap. In addition to IRMA’s built in quality control, MIRA requires a minimum median coverage of 100x, a minimum coverage of the reference length of 90%, and less than 10 minor variants >=5%. These are marked in yellow to orange according to the number of these failure types. Samples that failed to generate any assembly are marked in red. In addition, premature stop codons are flagged in yellow. CDC does not submit sequences with premature stop codons, particularly in HA, NA or SARS-CoV-2 Spike. Outside of those genes, premature stop codons near the end of the gene may be ok for submission. Hover your mouse over the figure to see individual results.



– – -
Review
MIRA Summary. This table shows assembly QC data for each reference identified and mapped to for each sample. Columns can be sorted and filtered, ie.>1000. ClickExportto save this as an Excel file.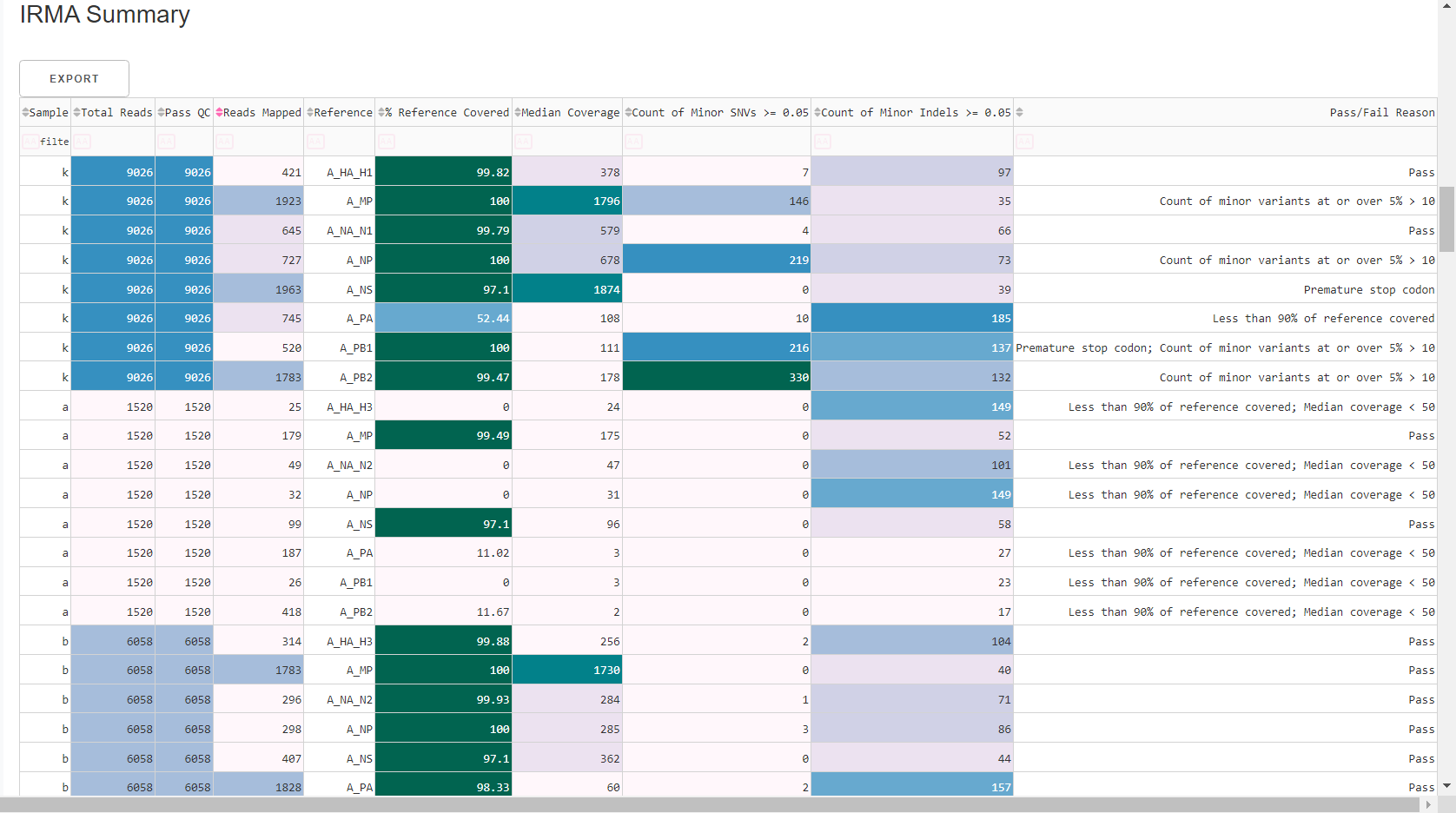
-
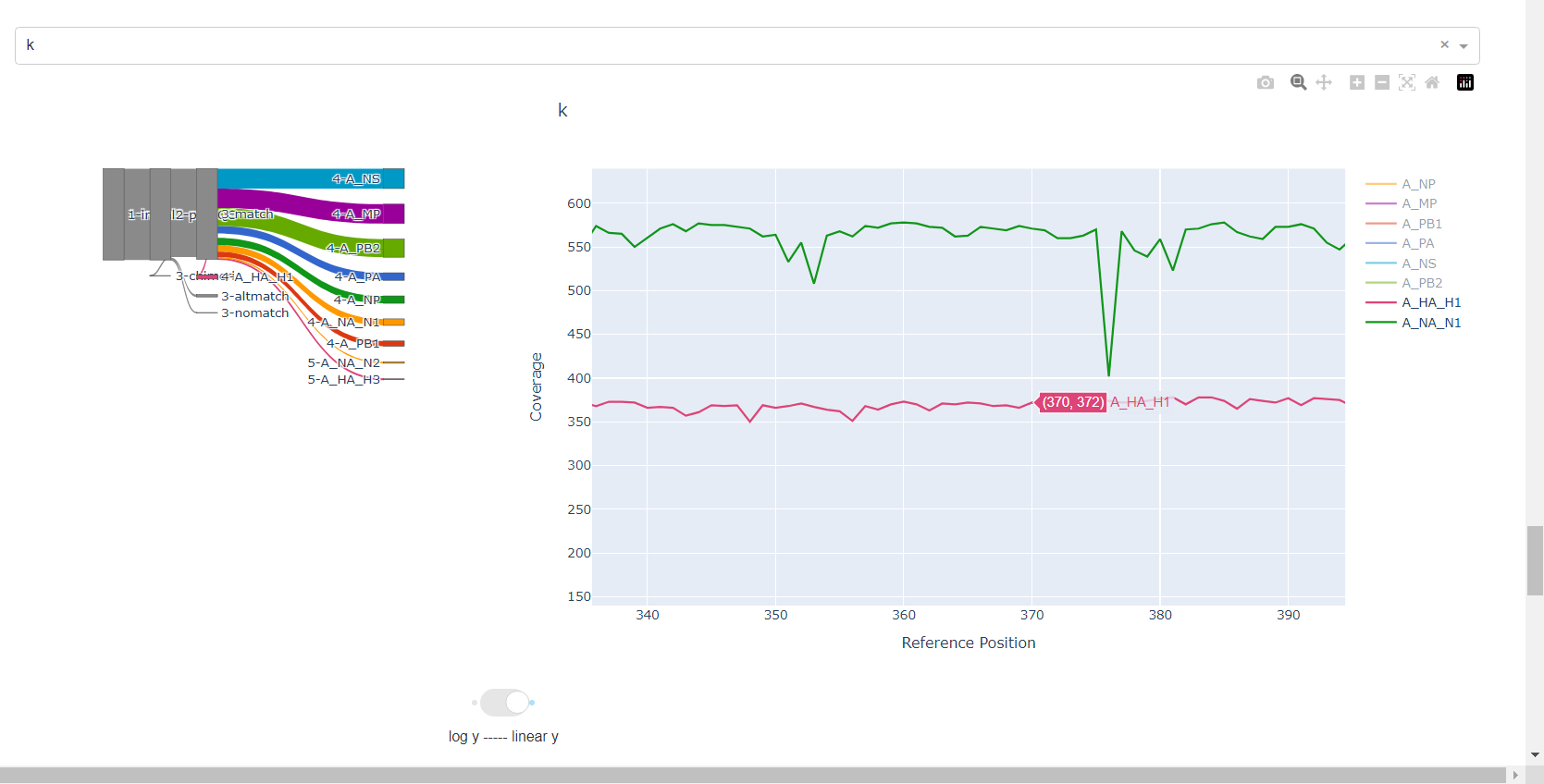
Review genome coverage depth. The heatmap summarizes the mean coverage per sample per gene. All the images in MIRA can be interacted with. Click the gray buttons on the top right of the images. The camera icon will save the image. Clicking on a sample in the heatmap, or selecting one in the drop down menu will display two plots. On the left is a “sankey plot” that shows the number of reads assigned to the barcode, how many of those passed IRMA’s QC, and how many are assigned to each gene reference. The plot on the right shows the sample’s complete coverage per gene. Try toggling the
log y --- linear ybutton. In log space, you likely need to reset the view by clicking the gray button in the top right that looks like an X inside of a box. You can also try panning and zooming the plot.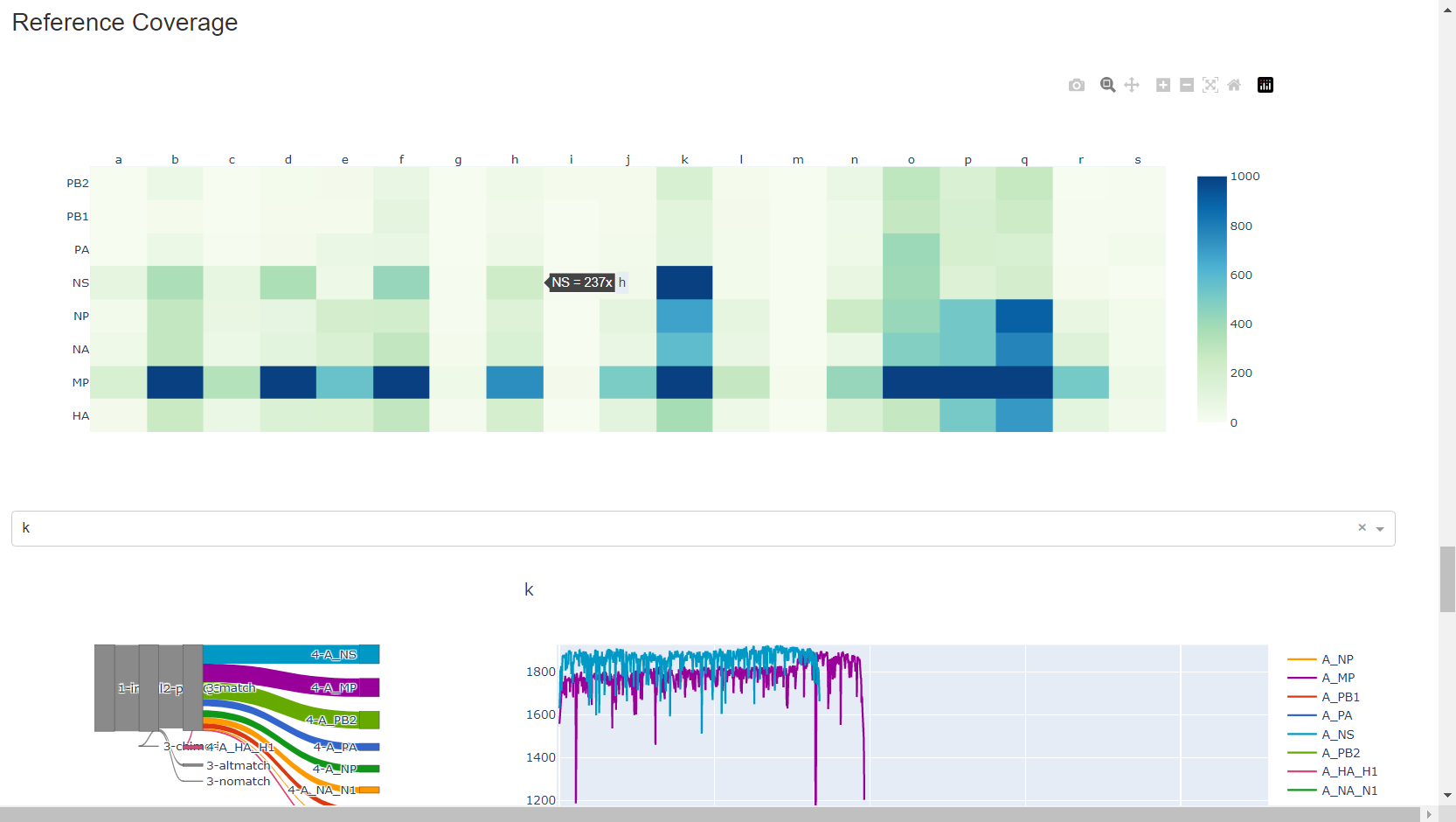
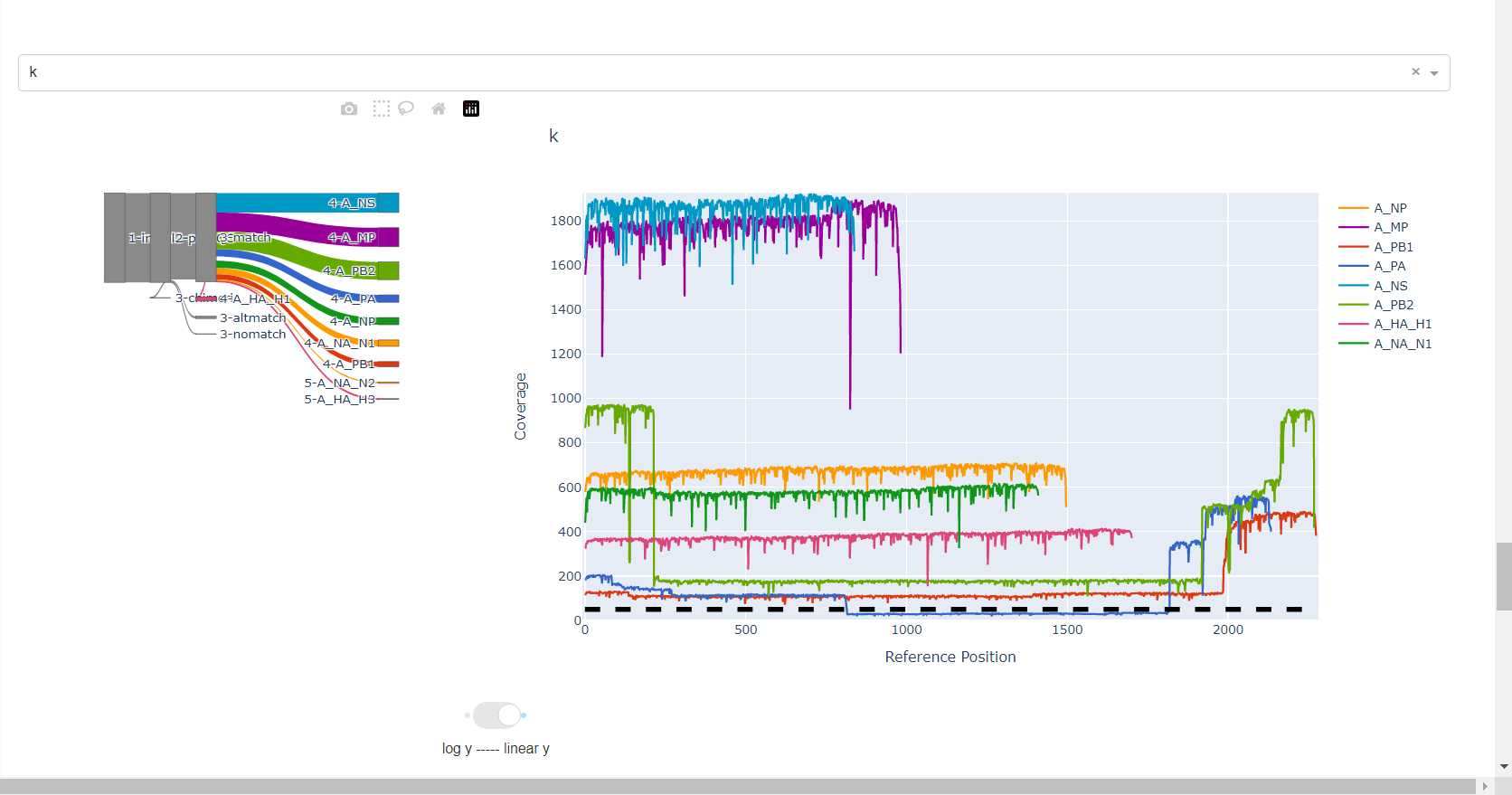
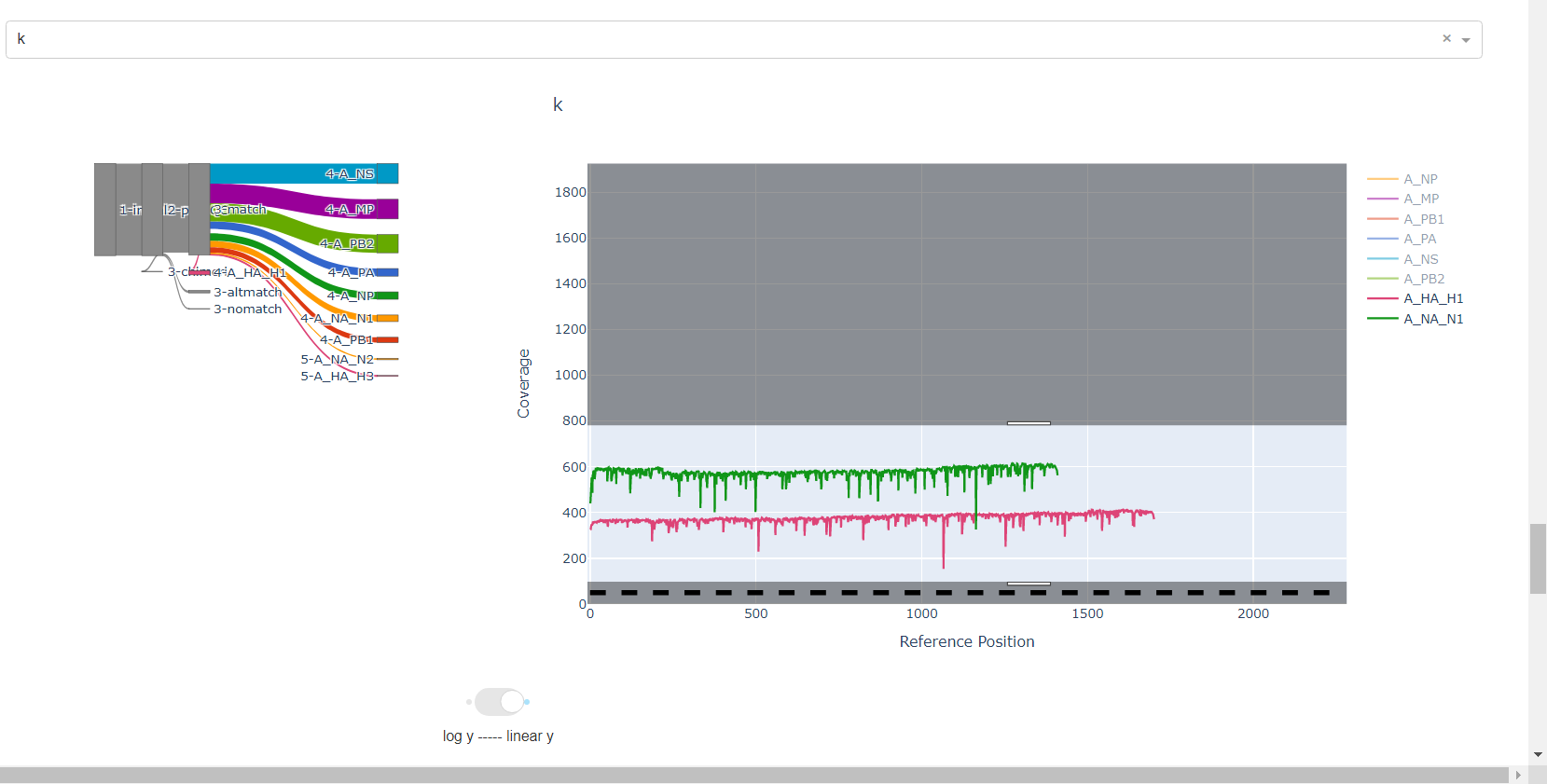
-
Inspect amino acid variants against popular reference sequences.
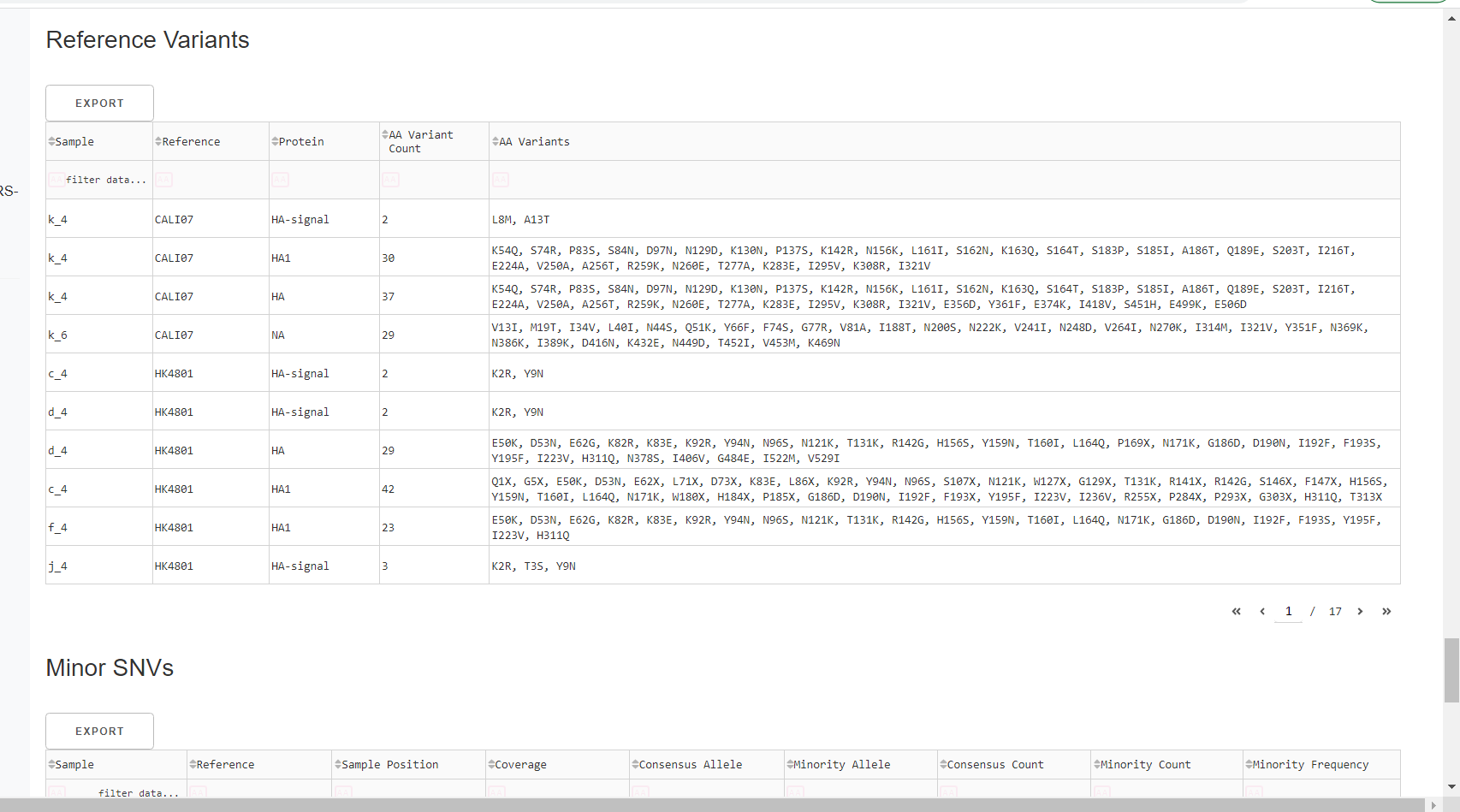
Here, you may see some mutations that do not match Amino Acid letters.
Special translated characters
Translation produces standard amino acid codes with the two non-standard exceptions (. and ~) listed below. The translation engine stops when it encounters a stop codon, but corrects itself to continue in-frame when a frameshift is encountered.
| Character | Interpretation |
|---|---|
| . | Missing alignment data |
| - | Gap in alignment (ex: deletion) |
| ~ | Partial codon (ex: frameshift) |
| X | Ambiguous codon translation |
-
Inspect minor variation at single nucleotides, insertions and deletions relative to the sample’s generated consensus sequence. These tables are for your own usage and not necessary to review in detail. They can be sorted and filtered and exported to excel sheets for further analyses.
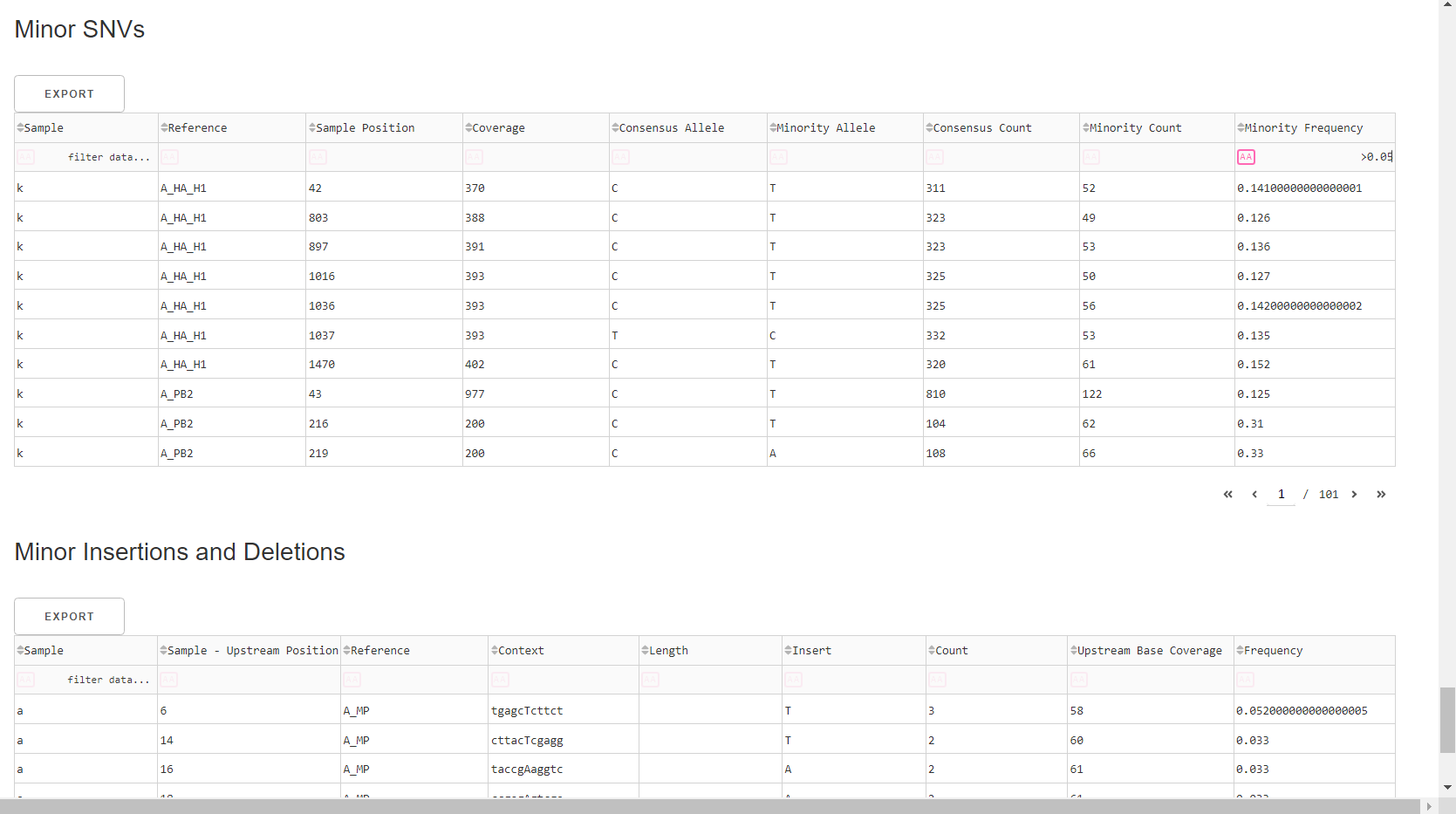
- Minor variants greater than 5% frequency are shown
- Indels greater than 20% frequency are shown
Save your sequences in a fasta file
-
Export MIRA’s amended consensus nucleotide sequences and amino acid fasta files. This includes only those passing MIRA’s QC criteria and are ready for submission to public databases!
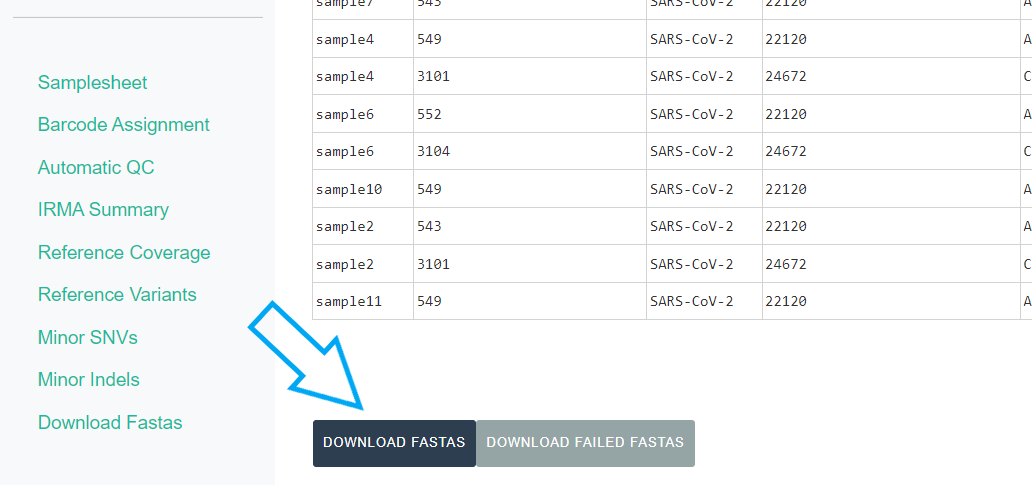
The
DOWNLOAD FASTASbutton will only return passing samples. To investigate failed sequences, click theDOWNLOAD FAILED FASTASbutton. Do not submit failed samples to public repositories!You can open and view these Amino Acid and Nucleotide fastas in any sequence viewing application

Wow! You are doing such great work. Time to share your sequences with the world by uploading to GISAID and/or NCBI and to start analyzing your own data!
- GISAID: https://gisaid.org/
- Please indicate in your GISAID submission “MIRA” for the
assembly methodmetadata field
- Please indicate in your GISAID submission “MIRA” for the
- NCBI-Genbank: https://www.ncbi.nlm.nih.gov/genbank/
- NCBI-BLAST: https://blast.ncbi.nlm.nih.gov/Blast.cgi
- Nextclade: https://clades.nextstrain.org/