

Our products
Our products create a data architecture that is:
- Flexible and modular
- Open source
- Easy to understand
- Easy to integrate with existing workflows
- Easy to test and implement
DIBBs Pipeline
A cloud-based data ingestion and processing pipeline that validates, cleans, standardizes, links, and stores public health data leveraging a core set of five Building Blocks. Public health departments can integrate our pipeline into their existing workflows to ingest and process multiple data streams (including eCR, ELR, ADT, and VXU) to create a single source of truth.
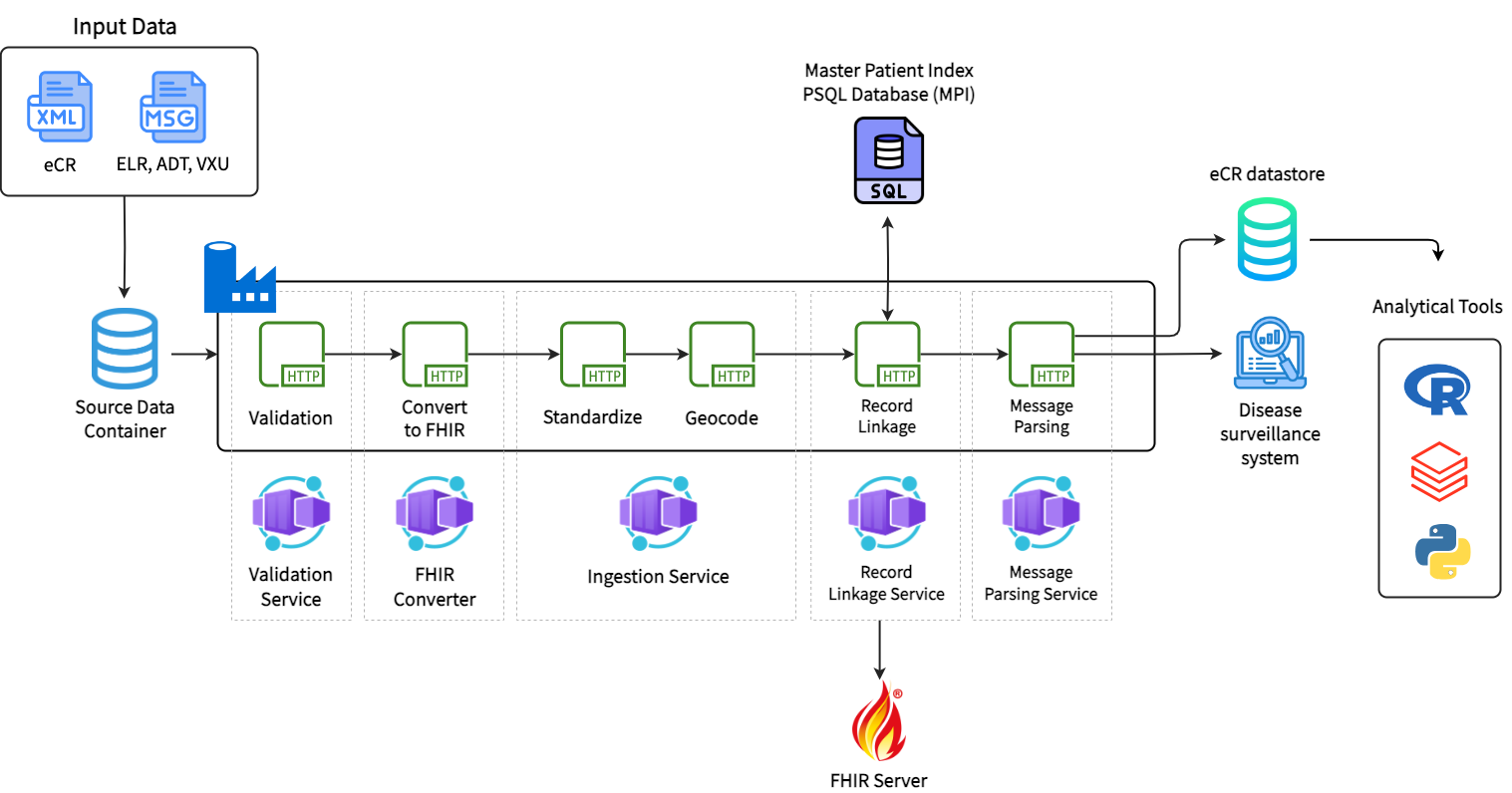
Building Blocks
Below, you will find a description of how the five core Building Blocks work to clean and transform data as part of the DIBBs pipeline. To see the full suite of containerized services, check out our containers repository.
Consists of two separate steps: (1) Standardization; (2) Geocoding
Standardization: Standardizes data fields (including record name, date of birth, phone number, and geolocation) based on preset defaults to ensure consistency
Geocoding: Enriches data by providing precise geographic locations based on patient street addresses from input data